Crawl website to create visual sitemap
Plans available to: All
Using this feature you can crawl a website to create a visual sitemap. Perfect for a website audit at the start of a redesign project!
It crawls the provided site and creates a structured visual sitemap based on the URL structure of the pages it finds.
- From your sitemap list page click on ‘New Project’ and select “Generate by Crawling a Website” which you will find in the dropdown.
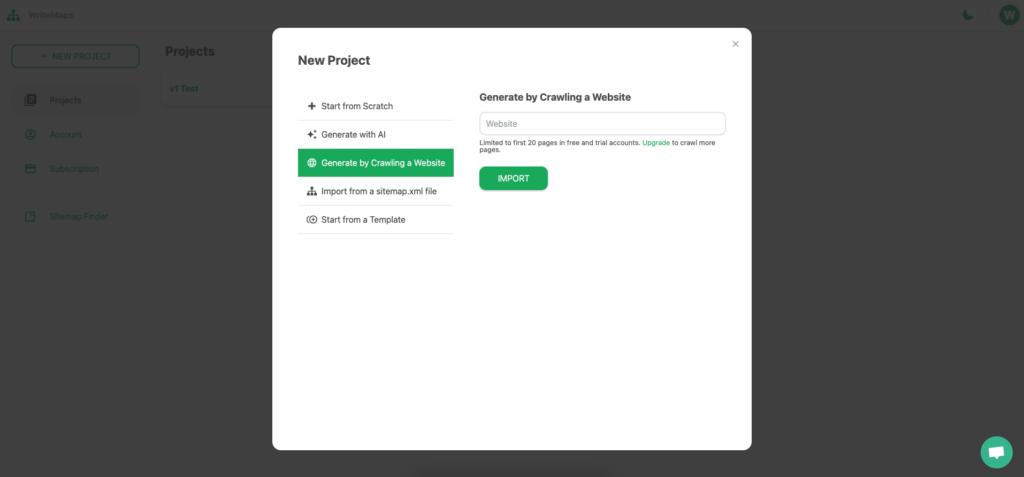
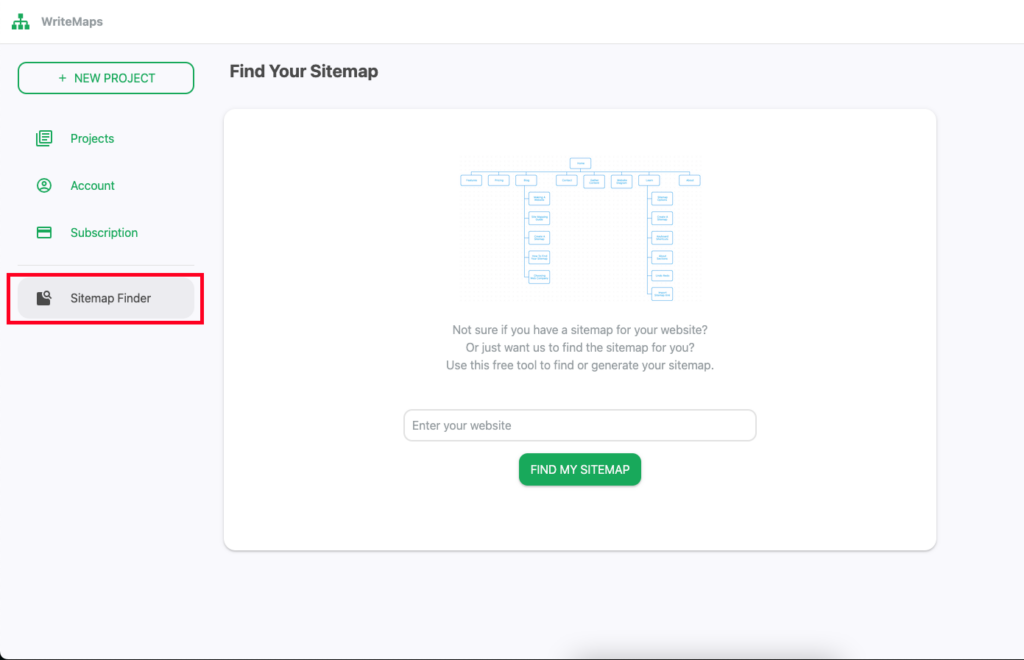
OR You can also select “Sitemap Finder” from the navigation bar on the left side of the screen.
- Paste the URL to your website.
- Click ‘Create’ or ‘Find my sitemap’ depending on the option you selected above, and the crawling begins!
Please allow up to 5 minutes for a crawl to take place for a 250-page website. We are adhering to best practice crawling which means not crawling too fast which can overload smaller sites.
You can close the menu and continue to use WriteMaps as normal. Your sitemap will appear in your sitemap list when crawling has finished.
Troubleshooting:
Website not found – This means the URL provided (and the variations we also attempted) returned 404 Page Not Found errors. Try and visit the website yourself, and if you can view it in a logged-out state then WriteMaps Crawler should be able to crawl it. Copy and Paste the URL to prevent typo errors.
Blocked by Robots.txt – adhering to best practice crawling means we respect what a robots.txt file says. If the site you are trying to crawl disallows a wide range of crawlers in it’s robots.txt file (normally found at yourwebsite.com/robots.txt) then this crawling feature may not work).
If your website has disallowed robots in your robots.txt file and you want to only allow WriteMaps, add ‘User-agent’: ‘WriteMaps Bot’ and ‘Disallow: ‘ to your robots.txt file.
My sitemap looks very flat – This crawler looks at your URLs which are non-structured data, and attempts to make a structured diagram out of them. If most of your webpages are not in sub-directories and are ‘flat’ e.g. yourwebsite.com/product1, yourwebsite.com/product2, then the sitemap will appear flat.
Why did my crawl fail?
The web crawling process can sometimes miss pages or fail completely due to various factors. Crawling a website involves retrieving and analysing web pages to index their content. However, several factors can lead to the failure of a web crawling process. Here are some common reasons:
- Robots.txt file: The website’s robots.txt file may disallow crawling of certain pages or the entire site for specific user agents, including web crawlers.
- Crawl delay: Some websites have a crawl delay specified in their robots.txt file, which instructs crawlers to wait for a certain period between requests. Ignoring this delay can lead to crawling issues.
- IP blocking or throttling: Websites may block or throttle the IP addresses associated with excessive or aggressive crawling. This is done to prevent abuse and protect server resources.
- User-agent filtering: Websites may block specific user agents or treat different user agents differently. Crawlers may need to disguise their user agent to avoid being blocked.
- CAPTCHA challenges: Websites may implement CAPTCHA challenges to verify that the user is human. Automated crawlers may struggle to overcome these challenges.
- Session-based restrictions: Some websites use session-based restrictions or require cookies for access. Crawlers may need to handle cookies to navigate such sites successfully.
- Dynamic content loading: Websites that heavily rely on JavaScript to load content may not be fully crawled by traditional web crawlers that do not execute JavaScript. Specialized tools or headless browsers may be required.
- Ajax and single-page applications (SPAs): Crawling SPAs and websites that heavily use Ajax may be challenging because the content is loaded dynamically after the initial page load. Traditional crawlers may not interpret these dynamic changes.
- Flash or Silverlight content: Crawlers may have difficulty processing and extracting information from websites that use Flash or Silverlight, as these technologies are less common and not well-supported.
- Large or infinite link spaces: Websites with an extensive number of pages or an infinite number of possible links may overwhelm crawlers, causing incomplete or inefficient crawling.
- Server errors: If the website’s server is experiencing issues, such as being down or responding slowly, the crawling process may fail.
- Duplicate content: Some websites may have duplicate content issues, causing crawlers to get stuck in an infinite loop or fail to index unique content properly.
- SSL/TLS issues: Crawling HTTPS websites may encounter problems if there are SSL/TLS certificate issues, expired certificates, or mismatched certificates.
- Geographic restrictions: Websites may implement access restrictions based on geographic locations, limiting the ability of crawlers from certain regions to access the content.
Rest assured, our dedicated tech team is actively working to enhance our technology and address these challenges.